I’m still reading The Scout Mindset: Why Some People See Things Clearly and Others Don’t by Julia Galef, but I’ve made it through Chapter 6: How Sure Are You? The chapter includes a fun exercise to answer a set of trivia questions, estimate a confidence level for each question, and then plot the results.
The goal is not to prove trivia prowess, but to see how well your confidence is calibrated (i.e., how close do you fall to the Y = X line where the percentage of questions answered correctly exactly matches the a priori estimated confidence).
At first glance, I was a little disappointed. I was 65% correct on my 65% confidence questions and 80% correct on 75% confidence (good start!), but then was 75% correct for 55% confidence and 100% for both 85% and 95% confidence. It seemed like I was sandbagging, which isn’t quite as bad as being overconfident but still nothing to brag about.
Then I realized since there were only 40 total questions and 5 allowable confidence levels (55%, 65%, 75%, 85%, and 95%) on average there are only 8 data points per estimate, which would result in large confidence intervals. For a set of Bernoulli trials, the 95% confidence interval given by the following equation (this is half the bound, so the ± value).
$$ CI_{0.95} = \frac{1.96}{n_{total} \sqrt{n_{total}}} \sqrt{n_{correct} n_{incorrect}} $$
Here’s what it looks like when I add these confidence intervals to my point estimates.
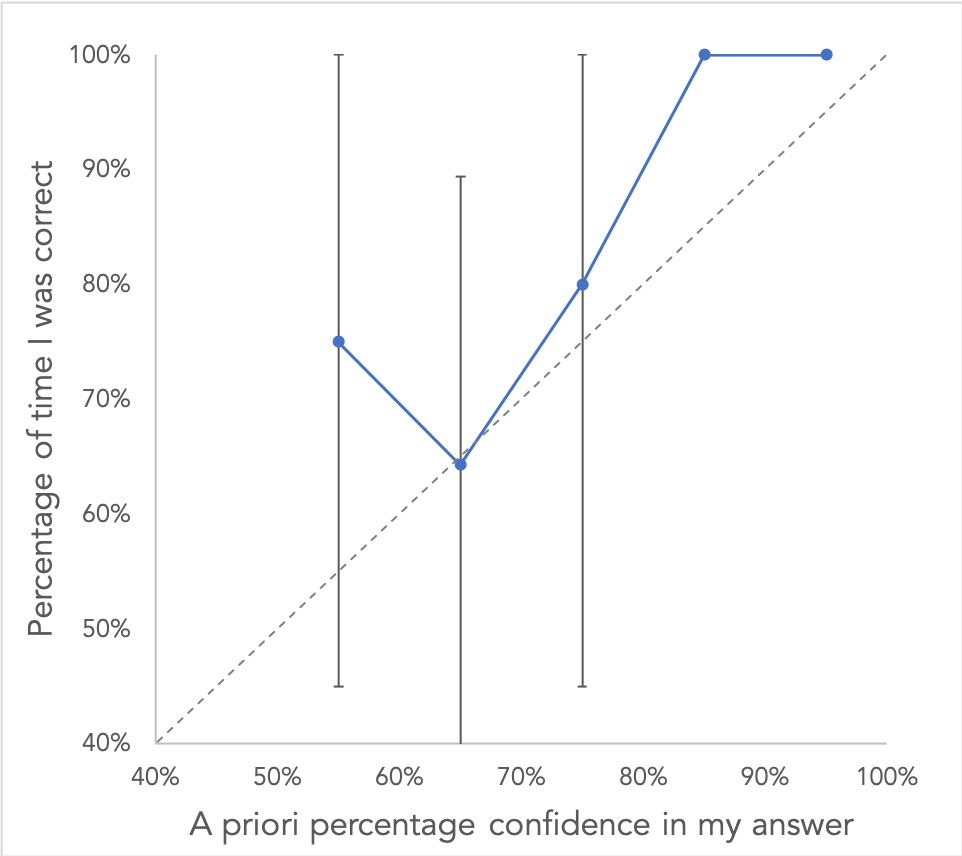
The three intervals contained the dashed Y = X line, so I felt a bit better, but there’s not much to glean from error bars as wide as ±35%.1
I’d feel good if the percentage of time I was correct was within ±5% of my answer confidence, so I decided to calculate the number of trials necessary to achieve a desired margin of error (in this case ±5%).2 With 95% confidence this is given by:
$$ 0.05 = 1.96 \times \sqrt{\frac{p \times \left(1-p \right)}{n}} $$
Where, $p$ is actual percentage of time I am correct, so for 55%: $$ 0.05 = 1.96 \times \sqrt{\frac{0.55 \times \left(0.45 \right)}{n}} \rightarrow n \approx 380 $$
For 95% the number of questions is much smaller, but I’m glad Julia left this an an interesting exercise and didn’t include a quiz large enough to generate statistically interesting results.
$$ 0.05 = 1.96 \times \sqrt{\frac{0.95 \times \left(0.05 \right)}{n}} \rightarrow n \approx 73 $$
If you’re curious, the questions were grouped into four categories (and here’s are the questions I missed in each category):
- Animal facts (flamingos are pink because they eat shrimp; camels store fat not water in their humps).
- Which historical figure was born first? (Gandhi was born before Castro; Joan of Arc before Shakespeare; Confucius before Julius Caesar) My worst category, both in percentage correct and lowest confidence.
- Which country had more people in 2019? (China still has more people than India; Haiti has more people than Jamaica 🤦🏻♂️)
- True or false science facts (brass is made from zinc and copper not iron and copper).
-
It gets worse, as I had to truncate the error bars for the 55% and 75% bins at 100% and couldn’t even calculate intervals for the 85% and 95% bins since I didn’t miss any of those questions. ↩
-
I’ve used this calculation many times to determine the number of Monte Carlo simulation runs required to estimate the probability of some discrete event. ↩